DFCL 的关键处理有四点:
- 在 RCT 数据上,用按 treatment 样本量校正的 factual loss 代替不可观测的全量 counterfactual MSE;
- 把预算约束的 primal MCKP 转成 Lagrangian dual,避免每个预算都反复调用大型 0-1 优化器;
- 用 policy learning loss、maximum entropy regularized loss 或 improved finite-difference 给 decision loss 提供可训练梯度;
- 训练目标最终是 ,用 保住预测基本面,用 让模型关注预算边界附近真正影响 allocation 的误差。

1. 论文定位:预测准确率和分配收益之间的错位
营销预算分配通常拆成两阶段:第一阶段用机器学习模型预测不同 treatment 下的 revenue / cost / uplift,第二阶段把预测值交给运筹优化器,在预算约束下求最优分配。这个流程的核心问题是目标不一致:模型训练时优化 MSE、Logloss 或 uplift ranking;业务上线时关心的是预算约束下的总 orders、GMV、revenue 或 ROI。
在 MCKP 中,预测误差对业务收益的影响高度不均匀。一个不会改变 的误差几乎不影响决策;而发生在预算边界或 treatment choice 边界附近的小误差,则可能让优化器选错折扣档位,造成明显的收益损失。DFCL 的方法定位就是把这种“决策敏感性”纳入训练。
与普通 DFL 相比,营销场景多了三个困难:
| 难点 | 普通 DFL 常见假设 | 营销 DFCL 的处理 |
|---|---|---|
| 预算不确定 | 约束或 feasible set 固定 | 用多预算/多 学习不同预算下的策略 |
| 反事实不可观测 | 可以直接评价完整真实参数下的决策 | 依赖 RCT,用 inverse treatment count / propensity 构造无偏估计 |
| 优化器调用昂贵 | 下游 solver 可以反复调用 | 利用 Lagrangian dual 分解,或用 IFD 增量更新加速 |
2. 问题设定:Multi-Treatment Budget Allocation Problem
论文把营销问题定义为 Multi-Treatment Budget Allocation Problem, MTBAP。有 个对象、 个 treatment。对象可以是用户、商家或商品;treatment 可以是折扣、券面额、补贴档位或 no treatment。
| 符号 | 含义 |
|---|---|
| 对象索引 | |
| treatment / action 索引 | |
| 对象特征 | |
| RCT 中实际分配给对象 的 treatment | |
| 对象 在 treatment 下的潜在 revenue / orders | |
| 对象 在 treatment 下的潜在 cost | |
| 是否给 分配 treatment | |
| 总预算 | |
| 模型预测的 revenue / cost | |
| Lagrange multiplier,预算影子价格 |
MTBAP 的 primal 形式为:
如果 已知,这是 multi-choice knapsack problem。营销系统中 不可直接观测,线上只能输入模型预测 ,求:
DFCL 的训练目标必须贴合这个 ,而不是只盯着 的逐点误差。
3. 反事实与 RCT:为什么 loss 要按 treatment count 校正
潜在结果框架下,每个对象只观测到 factual outcome:
未分配 treatment 的 都是 counterfactual。若完整 potential outcome surface 可观测,直接 MSE 为:
但真实训练集只能观测 对应项。DFCL 在 RCT 条件下使用:
其中 是 treatment 的样本数。Theorem 1 说明,在 randomized assignment 下, 与完整 在期望意义上等价。
4. Decision Loss:用真实收益评价预测诱导出的策略
给定 后,优化器产生 。如果完整真实 可知,预算 下的 decision loss 可写成:
负号表示最大化 revenue 等价于最小化 loss。由于预算在现实中波动,论文把多预算下的目标合并:
实现时可以用离散预算集合替代积分:
最终训练目标为:
控制 prediction loss 与 decision loss 的权衡。 太小会让模型过度围绕策略边界优化,可能牺牲基础泛化; 太大则退化回普通 two-stage 预测模型。
5. Lagrangian dual:把预算问题改写成每个对象的打分选择
primal MCKP 难以频繁求解,DFCL 使用 Lagrangian relaxation。对预算约束引入 :
给定 后,对象之间解耦,每个对象只需要选择:
可理解为预算影子价格。预算越紧, 越大,cost 惩罚越强;预算越宽, 越小,模型更愿意选择高成本高收益 treatment。
Theorem 2 的作用是建立 primal 与 dual 的关系:在大规模营销中,单个对象最大收益 相对总体最优值 很小,因此 Lagrangian/greedy 近似的比例接近 1:
dual decision loss 也因此可以作为训练目标的合理替代。
6. 三种梯度路径:PLL、MER、IFD
6.1 Policy Learning Loss, PLL
dual 下的 hard decision 是 indicator,不可微:
PLL 用 softmax 平滑这个选择:
若完整 可知,policy learning loss 等价于最大化 soft policy 的期望 reward。由于训练集中只有 factual outcome,DFCL 使用 RCT 校正后的 surrogate:
直观上,若某个 factual treatment 在真实 下净收益较高,模型应提高它在 softmax 下的概率。
6.2 Maximum Entropy Regularized Loss, MER
MER 从优化问题本身加入 entropy regularizer,并放松 到 :
解具有 temperature softmax 形式:
控制平滑程度。 大时选择更软,梯度更平滑; 小时接近 hard argmax,但训练更敏感。
6.3 Improved Finite-Difference, IFD
IFD 走另一条路:用 EOM 估计策略收益,再用 finite difference 估计 decision loss 对 的梯度。普通黑盒 finite difference 需要逐维扰动并反复调用 primal solver,百万级样本下成本很高。
改进之处在于利用 dual decomposition:给定 时,每个对象独立决策。对每个样本,先算出使 treatment choice 翻转的最小扰动,再只修正扰动后真正改变的部分,无需完整重算所有策略收益。因此 IFD 保留了黑盒估计的直接性,同时把“频繁求解 primal MCKP”换成了更可控的增量更新。
7. 离线实验:预测指标不等于决策质量
7.1 数据集
| 数据集 | 类型 | 规模与字段 | 用途 |
|---|---|---|---|
| CRITEO-UPLIFT v2 | public binary treatment RCT | 13.9M samples,12 features,treatment indicator,visit/conversion labels | 用 AUCC 评估二元 treatment 下的决策质量 |
| Meituan Marketing data | 美团折扣 RCT | 2.8M samples,107 features,5 个折扣 treatment:,daily cost/orders | 用 EOM 评估多 treatment 预算分配 |
7.2 Baselines
| 方法 | 含义 |
|---|---|
| TSM-SL | two-stage + S-Learner,先预测 response,再求 MCKP |
| TSM-CF | two-stage + Causal Forest |
| DPM | Direct Policy Matrix / decision factor 方向的 surrogate 方法 |
| CN | 带 treatment-outcome monotonic constraint 的 constrained network |
| CN+DFCL-PL | 在 CN 上加入 DFCL policy learning loss |
| DFCL-PL | 使用 policy learning loss 的 DFCL |
| DFCL-MER | 使用 maximum entropy regularized loss 的 DFCL |
| DFCL-IFD | 使用 improved finite difference 的 DFCL |
7.3 原始实验表与结论
Table 1:common metrics。 two-stage 方法在普通预测指标上不差,甚至可能更好;这正好说明预测指标和决策指标不一致。
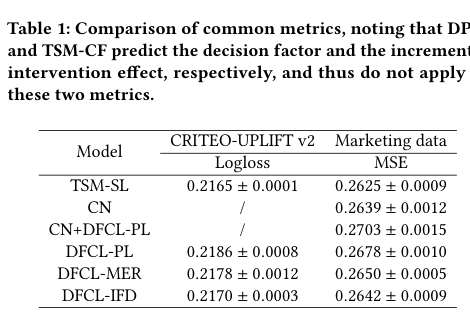
Table 2:CRITEO AUCC。 DFCL-IFD 达到 ,相对 TSM-SL 提升 ;DFCL-PL / MER 与 DPM 接近或略低于 IFD。
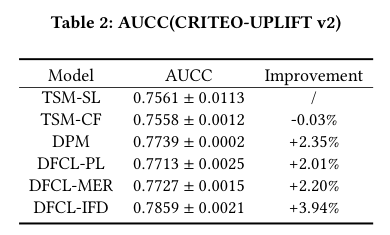
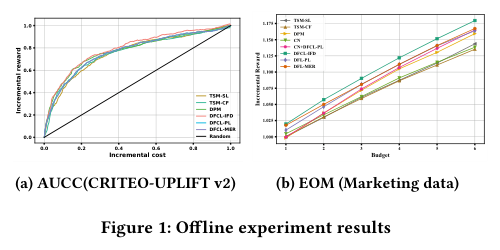
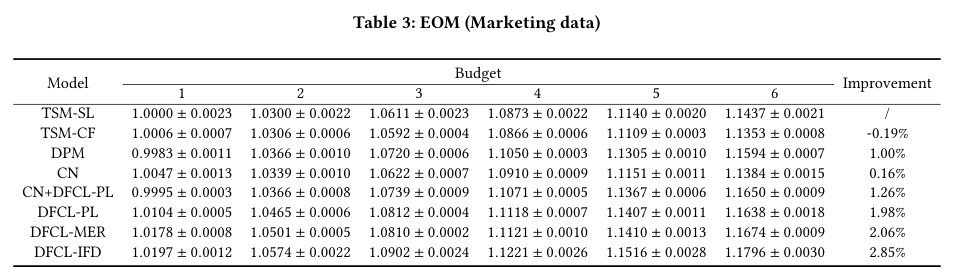
Figure 1 / Table 3:Marketing data EOM。 在美团多 treatment 数据上,DFCL 系列在不同 per-capita budget 下整体优于 baseline。Table 3 的 improvement 行显示:CN 为 ,CN+DFCL-PL 为 ,DFCL-PL 为 ,DFCL-MER 为 ,DFCL-IFD 为 。
8. Ablation:α 与 λ 决定训练落点
论文做了两个关键敏感性实验。
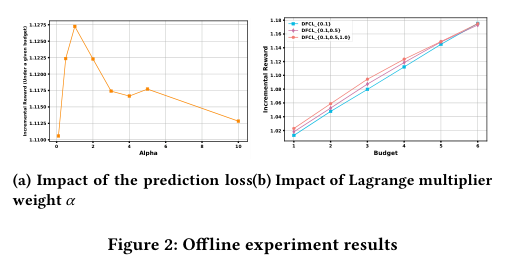
8.1 Prediction loss weight α
增大时,prediction loss 在训练目标中权重更高。实验显示,中等范围内加入 不会损害决策表现,还能让泛化更稳定;但 一旦过大,训练就退回普通 two-stage 方法,decision loss 的作用被一并淹没。
工程含义: 不是装饰性超参,应按离线 EOM / AUCC 或在线小流量指标调参,而不是只看 validation MSE。
8.2 Lagrange multiplier λ
不同 对应不同预算区间。小 更偏高预算策略,大 更偏低预算策略。论文比较了 、、,发现多 训练能更好平衡不同 budget 下的表现。
工程含义:如果线上预算每天波动,单个 容易过拟合某个预算区间;更稳妥的做法是从历史预算分布中采样多个 或预算点进行训练。
9. 在线 A/B:310K 商家、四周折扣实验
线上实验部署在美团折扣场景:310K online shops,每天随机分成 G-DFCL、G-DPM、G-TSM 三组。treatment 为 折扣档位,目标是在预算约束下最大化 orders。
部署流程:
- 每天 campaign 开始前,DFCL 模型预测各商家不同折扣下的 outcome / cost;
- 离线资源分配优化器根据预算与业务约束分配折扣;
- 用户访问商家并看到折扣,产生 orders / cost;
- 历史随机数据与优化器继续用于下一轮模型训练。
Appendix Table 4 给出四周 normalized orders 与置信区间。DFCL 平均相对 TSM-SL 提升 ,相对 DPM 提升约 。
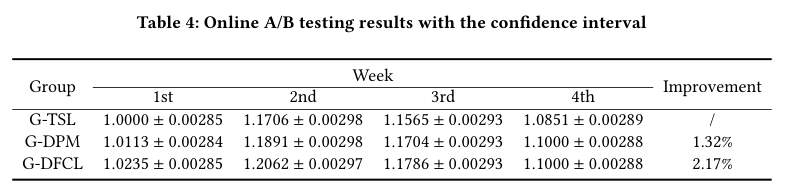
线上结果比离线更重要:它说明 decision-focused training 的收益不只是 counterfactual offline metric 上的曲线改善,也能转化为真实折扣系统中的 orders lift。
10. 复现重点
10.1 必要数据字段
| 字段 | 说明 |
|---|---|
| stable unit id | 用户/商家/商品等对象 ID,需能跨天对齐特征与 outcome |
| treatment id | 折扣/券/补贴档位,必须包含 no-treatment 或低成本档位 |
| known assignment probability | RCT 或 exploration policy 的 / treatment count |
| factual revenue / orders | 与业务目标一致的 outcome |
| factual cost | 与预算口径一致的成本,避免券发放成本、核销成本、补贴成本混用 |
| context features | 决策前可用特征,不能泄露 treatment 后变量 |
| budget and constraints | 每日预算、品类/商家/人群约束、风控规则 |
10.2 训练与评估顺序
- 用 RCT 数据训练 two-stage baseline,确认 、EOM、AUCC 或业务 offline evaluator 可跑通;
- 加入 DFCL-PL 或 DFCL-MER,先用小规模样本验证梯度、温度和 设置;
- 对大规模多 treatment 场景,评估 IFD 是否带来显著训练速度和策略收益提升;
- 用多个预算点或多个 做 validation,避免只优化单一预算;
- 离线通过后进入小流量 A/B,重点看 orders / GMV / incremental profit / cost overrun / 用户体验指标。
10.3 常见失败模式
| 风险 | 表现 | 排查方向 |
|---|---|---|
| RCT 不干净 | offline EOM 与 online A/B 不一致 | 检查分配概率异常、实验污染、干预跨组影响 |
| cost 口径错 | budget 满足但财务成本异常 | 券面额、核销成本、补贴结算周期口径是否统一 |
| 覆盖不足 | 某些预算区间表现差 | 从历史预算分布采样多 |
| 过大 | 指标接近 two-stage | 降低 prediction loss 权重,观察 EOM/AUCC |
| 过小 | 预测面不稳定,线上策略抖动 | 加强 或加 monotonic / smoothness 约束 |
| interference | 折扣影响竞争商家或用户跨店选择 | cluster randomization、市场级实验、延迟反馈建模 |
11. 与 Bi-DFCL 的关系
DFCL 是这一系列的基础版本:用 RCT 训练、用 decision loss 对齐 ML 与 OR、重点解决 prediction-decision misalignment。Bi-DFCL 进一步处理 DFCL 的两个瓶颈:
| 维度 | DFCL | Bi-DFCL |
|---|---|---|
| 训练数据 | 主要依赖 RCT | RCT + 大量 OBS |
| 核心矛盾 | 预测 loss 与决策收益不一致 | RCT 低偏高方差,OBS 高偏低方差 |
| 训练结构 | 单层 | 上层 RCT decision loss 训练 Bridge,下层 OBS prediction loss 训练 Target |
| 预算目标 | 多预算 / 多 dual loss | 更强调给定预算下的 primal decision loss |
| 上线模型 | causal model + optimizer | Target + optimizer,Bridge 训练期使用 |
因此,DFCL 更像“让反事实预测服务于分配决策”的第一步;Bi-DFCL 是“如何用小规模 RCT 指导大规模 OBS 训练”的第二步。
12. 落地判断
DFCL 的价值在于把 coupon / discount / subsidy 个性化从“预测任务”重新定义为“预测驱动的预算分配任务”。它特别适合以下条件同时成立的场景:
- treatment 档位有限且明确;
- 每个对象只能选一个 treatment;
- 总预算或 ROI 约束是真正的上线约束;
- 存在 RCT / randomized exploration 数据;
- 可以构建可信的 EOM / AUCC / policy evaluator;
- 线上允许按优化器输出做小流量 A/B。
不适合直接套用的场景也很清楚:历史日志存在严重选择偏差且缺乏 propensity,treatment 之间存在强干扰,成本或 outcome 延迟较长且归因不清,或上线决策包含大量难以形式化的业务规则。此时 DFCL 的 decision loss 可能优化的是有偏 evaluator,而不是实际业务收益。
总结:DFCL 的贡献不是提出一个更复杂的 uplift 网络,而是给出了一个从 RCT counterfactual evaluation 到 budget-constrained optimizer 的训练闭环。把“模型指标好不好”推进到“模型输出能不能让预算优化器选得更好”。