
1. 问题设定:营销不是单纯 uplift 排序,而是 MTBAP/MCKP
论文把营销问题形式化为 Multi-Treatment Budget Allocation Problem, MTBAP。有 个个体、 个 treatment。个体可以是用户、商家、商品或门店;treatment 可以是优惠券面额、折扣力度、补贴档位或不投放。
1.1 符号表
| 符号 | 含义 |
|---|---|
| 个体索引 | |
| treatment/action 索引 | |
| 个体特征 | |
| 样本 实际接受的 treatment | |
| 个体 在 treatment 下的潜在 revenue / outcome | |
| 个体 在 treatment 下的潜在 cost | |
| 分配决策, 表示给 分配 | |
| 总预算 | |
| allocation policy | |
| Target Network 对 revenue 的预测 | |
| Target Network 对 cost 的预测 | |
| Lagrange multiplier / 预算影子价格 |
潜在结果语境下,对每个样本 ,真实日志只观测到:
而其他 treatment 的 都是 counterfactual,无法直接观测。
1.2 Primal allocation problem
MTBAP 的 primal 形式是:
这是一个 multi-choice knapsack problem。每个个体必须从 个 treatment 中选一个,同时全局成本不能超过 。这比二分类 uplift 排序更接近真实的优惠券/补贴系统:要回答的不是“给不给券”,而是“给哪个档位、花多少预算、换来多少增量目标”。
1.3 Lagrangian relaxation:预算影子价格
论文用 Lagrangian relaxation 解近似分配。对预算约束引入 :
并保留每个个体只选一个 treatment 的约束。给定 后,个体之间解耦,每个 选择 adjusted score 最大的 treatment:
当使用模型预测时,实际 solver 用:
并选 。 可通过 binary search 找到,使 RCT/IPW 估计成本接近 per-capita budget 。
理解要点: 并非普通模型超参,而是 revenue 与 cost 的兑换率,也是预算的影子价格。若 、 的归因窗口、归一化、延迟回收口径不一致,错误的 会直接把优化器带偏。
2. 为什么不能简单拼 OBS + RCT
论文指出两个数据源的互补性:
| 数据源 | 优点 | 缺点 | 适合承担的角色 |
|---|---|---|---|
| treatment 随机,满足强可忽略性,可构造无偏 decision estimator | 昂贵、样本少、高方差、易过拟合 | 上层:评价/校正决策方向 | |
| 历史日志量大、覆盖广、低方差 | 受历史策略、选择偏差、位置偏差、未观测混杂影响 | 下层:提供大规模 prediction learning 信号 |
RCT 的关键假设是:
即 treatment assignment 与特征及潜在结果独立。因此在 RCT 上,只有当 policy 选择的 treatment 恰好等于随机分配的 treatment 时,样本的 observed outcome 才能用来无偏估计该 policy 的期望收益。
OBS 不满足该假设。若直接在 OBS 上最小化 decision loss,等于让历史投放策略的偏差直接进入优化目标,反而可能放大旧策略的选择偏差。若把 OBS 与 RCT 简单 concat,由于 OBS 样本远多于 RCT,OBS 会主导普通 loss,RCT 的无偏性也就被一并淹没。
Bi-DFCL 在结构上的取舍是:
也就是:RCT 进入上层 decision loss,OBS 进入下层 prediction loss。
3. 从 DFCL 到 Bi-DFCL:它到底新增了什么
DFCL 的基本目标可以写成:
其中 直接评价 downstream allocation 的质量, 约束预测误差。但 DFCL 主要在 RCT 上训练,因为 decision loss 的无偏估计依赖 RCT。这带来两个麻烦:
- variance 问题:RCT 样本少,训练出来的模型可能泛化差;
- loss balancing 问题: 是人工调节 prediction 与 decision 的权重,不能自适应利用 OBS/RCT。
Bi-DFCL 把这个加权和结构改成 bi-level:
解释:
- 是 Target Network 参数,是最终上线模型;
- 是 Bridge Network 参数;
- 给定 ,Target 在 OBS 上通过 训练得到 ;
- 上层拿这个 Target 到 RCT 上做 decision-quality 评估,并更新 Bridge;
- Bridge 的任务并非把 OBS prediction loss 本身压到最低,而是让“在 OBS 上训练出来的 Target”在 RCT decision objective 上更好。
这就是论文所谓的“bridging observational and experimental data”。
4. 三个网络:Teacher、Bridge、Target
Bi-DFCL 共包含三个网络,各有不同职责。
4.1 Target Network
Target 是最终上线模型。输入 ,输出所有 treatment 的 revenue/cost:
Serving 阶段只需要 Target:
4.2 Teacher Network
Teacher 在 RCT 上用普通 MSE/uplift loss 预训练,然后固定。它提供相对无偏但高方差的 counterfactual anchor:
它并非最终上线模型,上层 decision loss 也不会再去更新它。
4.3 Bridge Network
Bridge 输出 revenue gate 和 cost gate:
论文写成 ,但从实现角度看,Bridge 至少要感知个体/treatment 相关的表示,否则无法动态控制每个 上 OBS 的纠偏强度。论文在这里没有详述 Bridge 的输入特征,实现时需自行补足。
Bridge 用 gate 混合 Teacher 与 Target 生成 counterfactual pseudo-label:
直观理解:
- :更信 RCT Teacher,偏向低偏但高方差;
- :更信当前 Target/self-training,偏向低方差但可能继承 OBS 偏差;
- Bridge 所习得的是由 RCT decision quality 监督的 bias-variance 混合规则。
关键理解:Bridge 既不是简单的 propensity reweighting,也不是普通的 distillation。它在上层 RCT decision loss 的监督下学到的是“哪些 counterfactual 应当更信赖 RCT Teacher,哪些地方可以借助 OBS/Target 的低方差信号”。
5. 下层目标:OBS 上的 prediction loss 如何被 Bridge 参数化
对 OBS 样本 ,只有 factual treatment 下的 是实际观测到的。论文下层 loss 分两部分。
5.1 Factual loss
对 observed treatment 使用真实标签:
5.2 Counterfactual pseudo-label loss
对未观测 treatment ,使用 Bridge 生成的 pseudo-label:
合并得到下层 prediction loss:
注意这里 显式依赖 ,因为 counterfactual pseudo-label 由 Bridge 决定。上层只要调整 ,就能改写 OBS 上的训练目标,从而间接影响 Target。
5.3 一个实现上最容易踩坑的 detach 问题
公式中 pseudo-label 包含当前 Target 输出 和 :
如果实现时不 detach Target 在 pseudo-label 里的那一支,就会出现“模型追着自己跑”的梯度路径,loss 可能被抵消,或者出现意料之外的二阶依赖。论文正文未详细展开 detach 策略;从工程角度,至少需要明确:
- pseudo-label 生成时 Teacher 固定;
- pseudo-label 中 Target 的当前预测是否
detach; - upper assumed updates 与真实 lower updates 是否共享图;
- Bridge gate 是否允许通过 pseudo-label 回传到 。
复现时,这里应作为最优先排查的环节。
6. 上层目标:RCT 上的无偏 decision loss estimator
真实 decision loss 如果完整 counterfactual 可见,可以写为:
等价地,它是 policy 选择后的真实收益的负值。困难在于 不可全观测。
在 RCT 上,利用随机分配可得无偏估计:
其中 是 RCT 中被分到 treatment 的样本数,。如果实验不是均匀随机,实践中应该使用真实 logging probability 或设计概率,而不是 mini-batch 里的 。
预算约束也通过 RCT/IPW 估计:
这个估计器的含义非常具体:只有当 policy 选择的 treatment 恰好等于 RCT 随机分配的 treatment 时,样本的 observed outcome 才会被用来估计该 policy 的收益/成本。RCT 由此可以评价任意 policy,代价是估计方差较高。
7. Decision loss 不可微:PPL 与 PIFD
上层要更新 Bridge,需要上层 decision loss 对 Target 参数的梯度:
但 里有 和 indicator:
对 不可微。为此论文给出两种 primal surrogate:PPL 和 PIFD。
7.1 PPL:Primal Policy Learning Loss
PPL 用 softmax relaxation 替代 hard indicator:
更一般地带温度 :
于是:
解释:最大化 policy 在 observed RCT treatment 上的概率,并用该 treatment 的真实 reward 加权。由于 RCT treatment 随机,这个 soft policy objective 是给定预算 下 decision quality 的可微近似。
PPL 的优点:简单、稳定、可直接 autograd、和实际预算 对应的 对齐。
PPL 的缺点:softmax relaxation 改变了原始离散优化 landscape;score scale、温度、 的稳定性会影响训练。
7.2 为什么 primal 比 dual 更贴近实际预算
DFCL 原有 dual loss 会在多个人为指定的 上求和,近似覆盖“多个预算水平”。Bi-DFCL 强调 primal loss:先用 binary search 根据当前预算 求出 ,再训练模型在这个预算下的 policy。
这对营销系统更实际,因为日常活动通常是:
而不是对所有可能预算同时平均优化。预算会随日变化,但候选集是有限的;因此论文后面又验证了多个 budget level 下的鲁棒性。
7.3 PIFD:更接近原始离散 decision loss 的有限差分
PIFD 试图估计:
然后冻结这个梯度,把 surrogate 写成:
附录里的原始有限差分是:
但逐元素扰动太慢,论文因此提出 -aware gradient estimator:先用 solver 得到 和当前分配,再根据当前最佳 action 与 treatment 的 score margin 估计最小扰动 。核心 score 是:
若 RCT observed treatment 正好匹配 policy,即 ,则把 推离当前最优所需 margin 是:
若不匹配,则设 ,需要把 推到超过当前最优:
然后用 除以 margin 得到近似梯度。这个设计的直观理解是:越接近决策边界的样本,微小预测改变越可能改变 OR 解,因此对 decision loss 的梯度影响越大。
PIFD 的优点:比 PPL 更贴近 hard optimization landscape。
PIFD 的缺点:实现复杂,margin 接近 0 时数值不稳;符号、detach、梯度冻结、budget solver 的一致性都容易错。
8. Bridge 的上层梯度:隐式微分 + CG
Bi-level 的核心梯度是:
前一项由 PPL/PIFD 解决。后一项是 lower optimum 对 Bridge 参数的 Jacobian。
8.1 下层一阶最优条件
若 是下层问题的局部最优,则:
对 求导:
令:
则:
因此 upper gradient 可理解为:
实际不显式求 Hessian 逆,而是解线性系统。
8.2 CG 与 Hessian-vector product
要解:
其中 与 或混合二阶项相关。CG 只需要 Hessian-vector product:
这可以用 autograd 二次求导完成,不需要显式构造 。论文默认:
其中 是 assumed lower GD steps, 是 CG 迭代次数。
8.3 为什么不用 explicit differentiation
显式微分假设:
于是:
这只在“一步 GD 就能到达下层最优”的假设下成立,对现实而言过强。多步展开又会带来显存、路径依赖和 vanishing gradient 等问题。隐式微分的好处是只依赖最优性条件,无须保存整条优化轨迹。
9. 完整训练流程:Algorithm 1 的工程拆解
算法可以拆成两个循环:upper update 更新 Bridge,lower update 更新 Target。
9.1 输入
模型包括:
9.2 步骤
- 预训练 Teacher:在 RCT 上用普通 MSE/uplift loss 训练 ,然后固定。
- 初始化 Target 和 Bridge: 可随机初始化或 warm start; 随机初始化。
- 每个 OBS mini-batch 做 lower update:用当前 Bridge 生成 pseudo-label,更新真实 Target 。
- 每 个 OBS batch 做 upper update:
- copy 当前 Target 得到 ;
- 对 copy 做 步 lower assumed updates,得到近似 ;
- 在 RCT batch 上用 PPL/PIFD 计算 decision gradient;
- 用 implicit differentiation + CG 求 ;
- 更新 Bridge 。
- 输出 Target:最终只保留 。
9.3 伪代码理解版
pretrain Teacher F_psi on RCT, freeze psi
initialize Target F_theta, Bridge G_phi
for OBS mini-batch B_obs:
if batch_index % k == 0:
theta_copy = copy(theta)
for step in 1..k:
pseudo labels = Bridge(Teacher, Target copy, B_obs)
theta_copy <- theta_copy - lr * grad_theta L_PL(phi, theta_copy; B_obs)
compute upper loss on RCT using theta_copy:
L_upper = L_PPL or L_PIFD
solve implicit linear system by CG
update phi
pseudo labels = Bridge(Teacher, current Target, B_obs)
theta <- theta - lr * grad_theta L_PL(phi, theta; B_obs)最重要的工程结论:上线时没有二阶微分、没有 Bridge、没有 Teacher;复杂性都在离线训练期。
10. 框架图
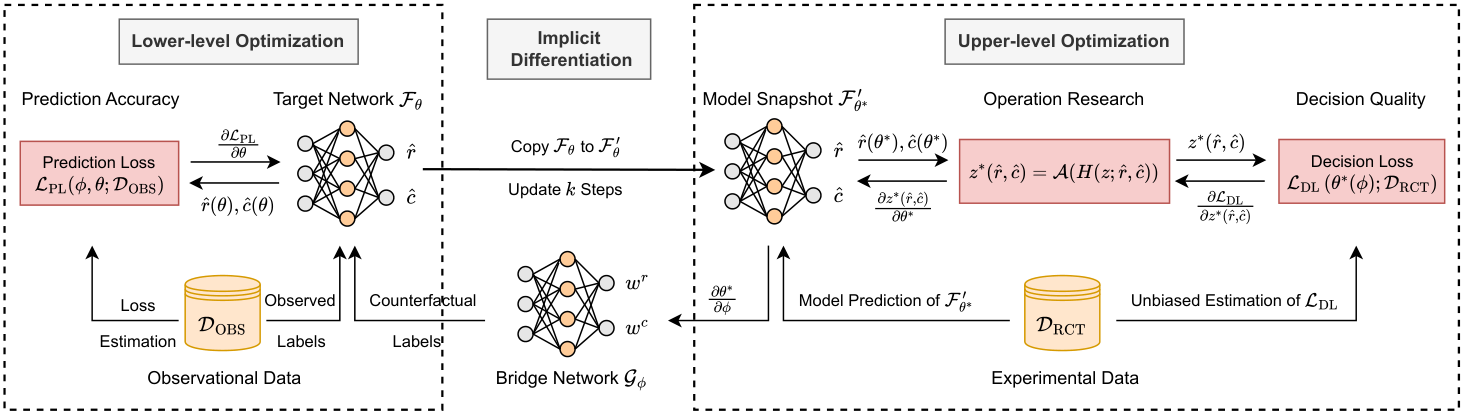
这张图的核心不是三个网络本身,而是监督信号的方向:
也就是 RCT 不和 OBS 平级拼接,而是控制 OBS 的使用方式。
11. 离线实验设计
11.1 数据集
| Dataset | Features | Treatments | OBS train | RCT train | RCT val | RCT test | Metric |
|---|---|---|---|---|---|---|---|
| CRITEO-UPLIFT v2 Hybrid | 12 | 2 | 3,498,294 | 698,980 | 1,397,959 | 4,193,878 | AUCC |
| Marketing Data I | 180 | 8 | 22,201,405 | 2,220,781 | 555,014 | 2,775,976 | EOM |
| Marketing Data II | 192 | 5 | 33,815,274 | 2,017,450 | 504,362 | 2,521,813 | EOM |
Criteo 的 hybrid 构造方式很重要:原始 Criteo 是 RCT,论文先用 5% 数据训练一个 two-stage model,再用该模型模拟 marketing policy,并挑出“模拟策略的 assignment 与真实随机 assignment 一致”的样本作为 OBS。这就构造出一个更像真实历史投放日志的 biased OBS。论文报告该构造 OBS 的 ROI 比随机数据高 82.43%,说明它确实不像随机实验,而更像经过策略选择后的日志。
11.2 指标
- AUCC:用于 Criteo binary treatment,衡量 ROI ranking / cost curve quality。
- EOM:Expected Outcome Metric,用 RCT/IPW 估计任意 budget allocation policy 的 per-capita revenue/cost。其计算本质与上层 decision estimator 一致:
11.3 Baselines
论文的 baseline 分三组,设计比较合理:
- RCT-only:TSM-SL, TSM-CF, DHCL, DFCL-DPL, DFCL-DIFD, DFCL-PPL, DFCL-PIFD。
- OBS-only:TSM-SL, TSM-CF, IPS, DR-JT, CFR-WASS, CFR-MMD, DragonNet。
- RCT+OBS:TSM-SL, CausE, KD-Label, KD-Feature, LTD-IPS, LTD-DR, AutoDebias。
这三组分别回答:只用无偏小样本够不够、只用有偏大样本会怎样、简单融合 OBS/RCT 是否足够。
12. 主结果:Bi-DFCL 是否真的赢
Table 2 报告 20 runs 的 mean ± std。
| Method | CRITEO AUCC | CRITEO 提升 | Marketing I EOM | Data I 提升 | Marketing II EOM | Data II 提升 |
|---|---|---|---|---|---|---|
| TSM-SL RCT | 0.7143 ± 0.0299 | — | 1.0000 ± 0.0032 | — | 1.0000 ± 0.0020 | — |
| 最强 RCT-only | DFCL-DIFD 0.7441 | +4.17% | DFCL-PIFD 1.0170 | +1.70% | DFCL-PPL 1.0156 | +1.56% |
| 最强 OBS-only | DragonNet 0.7490 | +4.86% | DR-JT 1.0102 | +1.02% | DR-JT 1.0054 | +0.54% |
| 最强 RCT+OBS baseline | LTD-DR 0.7533 | +5.46% | AutoDebias 1.0175 | +1.75% | LTD-DR 1.0067 | +0.67% |
| Bi-DFCL-PPL | 0.7797 ± 0.0094 | +9.16% | 1.0277 ± 0.0024 | +2.77% | 1.0252 ± 0.0023 | +2.52% |
| Bi-DFCL-PIFD | 0.7812 ± 0.0084 | +9.37% | 1.0297 ± 0.0030 | +2.97% | 1.0249 ± 0.0018 | +2.49% |
结果解读:
- Criteo 上 Bi-DFCL 比最强 RCT+OBS baseline 还高约 2.8 个 AUCC 点,说明它不是只靠多数据量;
- Marketing I/II 上 2.5% 到 3% 的 EOM 提升,在成熟营销预算优化系统里不小;
- PIFD 未必显著优于 PPL:Data II 上 PPL 的 1.0252 反而略高于 PIFD 的 1.0249。这说明更接近 hard-landscape 的复杂近似并非必然占优,PPL 反而可能是更稳的工程起点。
13. 消融:每个组件是否有贡献
论文逐步加入四个组件:Decision Loss、Bi-level、Counterfactual Labels、Implicit Differentiation。
| Decision Loss | Bi-level | Counterfactual Labels | Implicit Diff | Data I EOM | Data I 提升 | Data II EOM | Data II 提升 |
|---|---|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | ✗ | 1.0000 | — | 1.0000 | — |
| ✓ | ✗ | ✗ | ✗ | 1.0167 | +1.67% | 1.0156 | +1.56% |
| ✓ | ✓ | ✗ | ✗ | 1.0240 | +2.40% | 1.0175 | +1.75% |
| ✓ | ✓ | ✓ | ✗ | 1.0248 | +2.48% | 1.0213 | +2.13% |
| ✓ | ✓ | ✓ | ✓ | 1.0277 | +2.77% | 1.0252 | +2.52% |
更细地看:
- Decision Loss:从 1.0000 到 1.0167/1.0156,说明直接面向 downstream budget decision 是核心收益来源之一;
- Bi-level:Data I 从 1.0167 到 1.0240,说明 RCT upper / OBS lower 这种组织方式有额外收益;
- Counterfactual Labels:Data II 从 1.0175 到 1.0213,说明 Bridge 生成 pseudo-label 比只做 dynamic reweighting 更有效;
- Implicit Differentiation:最终从 1.0248 到 1.0277、从 1.0213 到 1.0252,证明 ID 不是只为理论优雅,也能带来实测收益。
附录解释 Row 3 不是 counterfactual pseudo-label,而是一个 improved IPW:Bridge 直接输出动态 reweighting weight。Row 4 才开始使用 pseudo-label,但仍是 explicit differentiation。Row 5 是完整 ID。
14. 数据量分析:少量 RCT 能否校正大量 OBS
Marketing Data I 上的数据量实验:
| Method | OBS | RCT | OBS:RCT | EOM | 提升 |
|---|---|---|---|---|---|
| TSM-SL | 2,220,781 | 0 | — | 0.9869 | -1.31% |
| TSM-SL | 0 | 2,220,781 | — | 1.0000 | — |
| TSM-SL | 22,201,405 | 0 | — | 1.0067 | +0.67% |
| Bi-DFCL-PPL | 22,201,405 | 222,000 | 100.01:1 | 1.0190 | +1.90% |
| Bi-DFCL-PPL | 22,201,405 | 1,100,000 | 20.18:1 | 1.0258 | +2.58% |
| Bi-DFCL-PPL | 22,201,405 | 2,220,781 | 10.00:1 | 1.0277 | +2.77% |
这张表对业务最有启发:
- 小 OBS-only 反而低于 RCT baseline,说明有偏日志不能盲信;
- 大 OBS-only 有提升,但有限;
- 只用约 22.2M OBS + 222K RCT,就已经有 +1.90%,说明小流量随机实验可以作为方向校正器;
- RCT 更多时继续提升,但边际收益变小。
这支持这样一种实践架构:保留持续的小流量 RCT 或探索桶作为上层评估器,而不必为了训练就投入大规模随机流量。
15. 预算鲁棒性
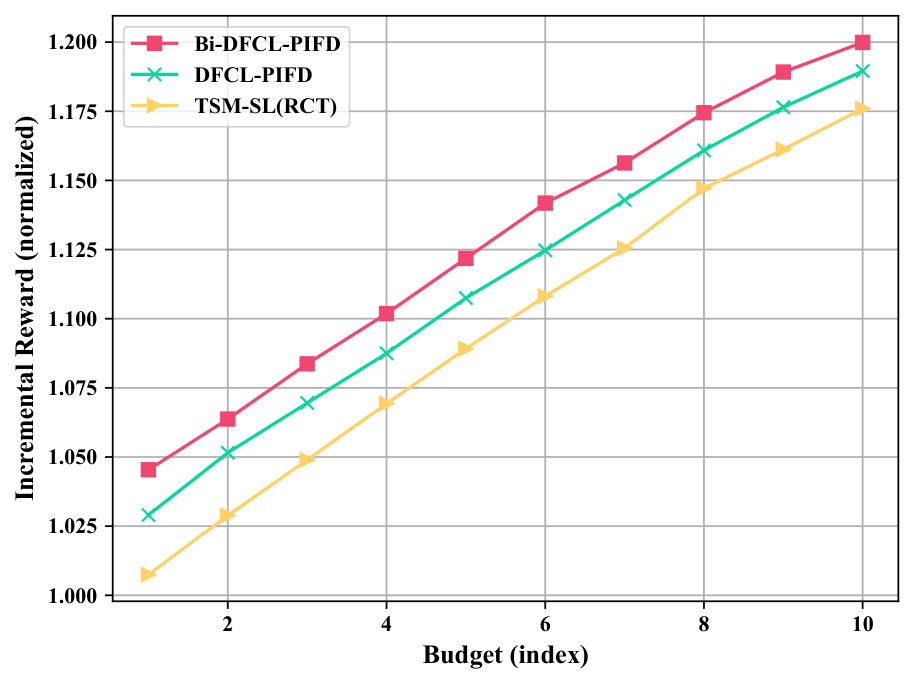
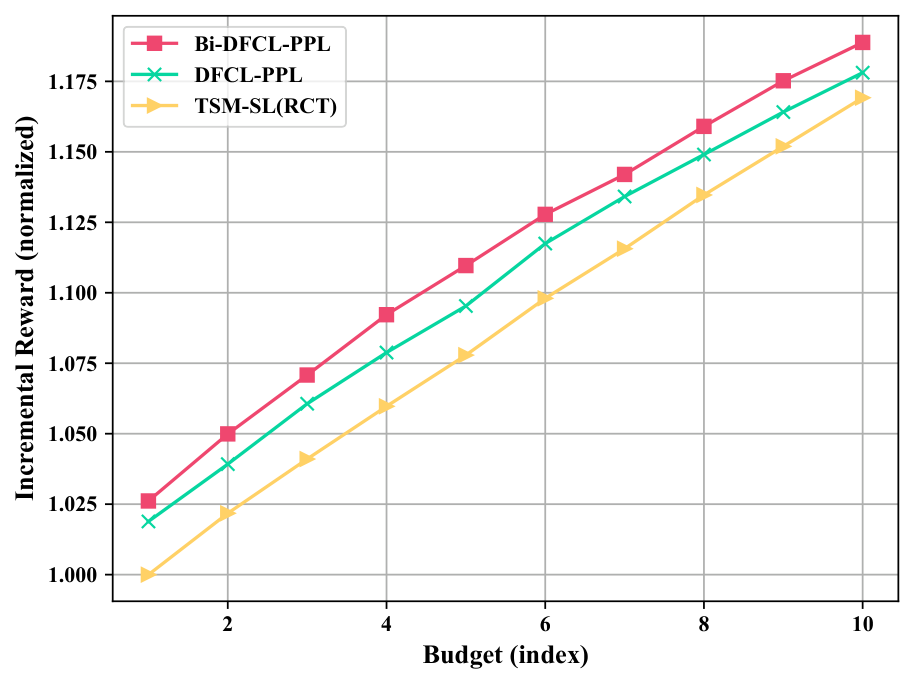
这两张图回答一个关键实践问题:PPL 使用特定预算 对应的 ,会不会只过拟合单个 budget?论文在多个 candidate budget level 下评估,Bi-DFCL 整体高于 TSM/DFCL/LTD 等方法。
对优惠券系统,这一点很重要:活动预算、类目预算、城市预算会每天变化。如果模型只在一个 上好,就很难进生产。论文结果支持 Bi-DFCL 具有一定 budget robustness,但注意它仍然是在有限候选预算集上验证,不等于任意预算连续泛化都有保证。
16. 超参、模型结构与训练成本
16.1 模型结构
附录给出 MLP 结构:
| Dataset | 模型结构 | 输出解释 |
|---|---|---|
| Criteo | 64-32-32-4 | 2 个 revenue + 2 个 cost |
| Marketing I | 128-64-32-16 | 8 个 revenue + 8 个 cost |
| Marketing II | 128-64-32-10 | 5 个 revenue + 5 个 cost |
Target、Bridge、Teacher 默认使用相同结构。训练使用 Adam;Criteo 100 epochs,两个工业数据集 500 epochs;默认 warm-start 20 epochs;两张 A100,总显存 232GB。
16.2 与 敏感性
Marketing Data II:
| EOM | 提升 | ||
|---|---|---|---|
| 1 | 10 | 1.0199 | +1.99% |
| 1 | 50 | 1.0217 | +2.17% |
| 5 | 10 | 1.0230 | +2.30% |
| 5 | 50 | 1.0252 | +2.52% |
| 5 | 100 | 1.0253 | +2.53% |
| 5 | 200 | 1.0249 | +2.49% |
| 10 | 50 | 1.0255 | +2.55% |
| 10 | 100 | 1.0252 | +2.52% |
解读:
- 时 ID 优势有限,因为一步 lower update 太不像下层最优;
- 已经接近稳定;
- 超过 50 后收益很小;
- 实践可以从 开始,优先调 learning rate、预算求解稳定性和 pseudo-label detach,而不是盲目加 CG 次数。
16.3 训练时间
Marketing Data II,500 epochs:
| Method | Data | Time min | Relative |
|---|---|---|---|
| TSM-SL | RCT | 2.505 | 0.06× |
| DFCL-PPL | RCT | 3.163 | 0.07× |
| DFCL-PIFD | RCT | 9.948 | 0.23× |
| TSM-SL | OBS | 39.918 | 0.94× |
| TSM-SL | RCT+OBS | 42.332 | 1.00× |
| KD-Label | RCT+OBS | 67.358 | 1.59× |
| LTD-DR | RCT+OBS | 492.559 | 11.63× |
| AutoDebias | RCT+OBS | 397.886 | 9.40× |
| Bi-DFCL-PPL | RCT+OBS | 265.263 | 6.26× |
| Bi-DFCL-PIFD | RCT+OBS | 294.927 | 6.96× |
| Bi-DFCL-PPL w/o ID | RCT+OBS | 345.132 | 8.15× |
| Bi-DFCL-PIFD w/o ID | RCT+OBS | 427.515 | 10.10× |
Bi-DFCL 训练明显更贵,但比 LTD-DR/AutoDebias 更快。更重要的是,线上 inference 与普通 Target 模型相同,因此训练成本主要是离线问题。
17. 线上 A/B
线上实验在美团外卖营销场景:
- 约 790K online shops;
- 四周;
- 每天随机分为五组:G-BPPL、G-BPIFD、G-PIFD、G-LTD、G-TSL;
- treatment 为折扣 ,含义是订单满门槛后 off;
- 目标是在每日预算约束下最大化订单数。
| Method | Week 1 | Week 2 | Week 3 | Week 4 | Overall improvement |
|---|---|---|---|---|---|
| TSM-SL | 1.0000 ± 0.0022 | 1.0335 ± 0.0030 | 0.9217 ± 0.0017 | 0.9720 ± 0.0048 | — |
| LTD-DR | 1.0183 ± 0.0020 | 1.0378 ± 0.0039 | 0.9344 ± 0.0037 | 0.9723 ± 0.0070 | +0.91% |
| DFCL-PIFD | 1.0302 ± 0.0013 | 1.0436 ± 0.0020 | 0.9440 ± 0.0020 | 0.9799 ± 0.0018 | +1.80% |
| Bi-DFCL-PPL | 1.0428 ± 0.0019 | 1.0558 ± 0.0025 | 0.9582 ± 0.0019 | 0.9872 ± 0.0014 | +3.00% |
| Bi-DFCL-PIFD | 1.0470 ± 0.0021 | 1.0537 ± 0.0027 | 0.9581 ± 0.0024 | 0.9906 ± 0.0031 | +3.22% |
这是论文中最有说服力的证据:Bi-DFCL 不只是 offline EOM 好看,而是在真实预算约束折扣分配中超过 DFCL-PIFD 与 LTD-DR。
但也要注意限制:
- 只披露 normalized orders,没有绝对订单量;
- 没披露预算消耗、ROI、profit、补贴率、长期留存;
- 没披露各商家分层、城市/类目异质性;
- 没说明是否有 spillover/interference,例如商家之间竞争与用户迁移。
所以线上结果是强证据,但不是完整业务评估。
18. 与优惠券/权益个性化场景的对应
如果映射到电商优惠券/权益发放:
| Paper 符号 | 电商含义 |
|---|---|
| 用户、用户-商品对、用户-店铺对、会员、商家 | |
| 不发券/券面额/折扣档位/免邮/满减门槛组合 | |
| GMV、订单、毛利、留存、复购、平台净收益 | |
| 券成本、补贴、商家承担成本、平台预算消耗 | |
| 活动预算、日预算、人群预算、商家预算 | |
| RCT | 小流量随机优惠实验或 exploration bucket |
| OBS | 历史营销投放日志 |
| Target | 线上打分模型 |
| Solver | 预算分配器 / MCKP / Lagrangian ranking |
最有价值的启发是:随机实验不一定要大到能单独训练强模型,它可以作为上层评估器,持续校正如何使用海量 OBS。
这比“要么全靠历史日志,要么全靠 A/B 实验”的二元思路更实用。
19. 实践路线:如果要做最小可行原型
直接复现完整 Bi-DFCL-PIFD + ID 风险较高。更稳的分阶段路线:
Stage 1:RCT-only DFCL-PPL baseline
需要:
- multi-head Target,输出 ;
- Lagrangian solver/binary search ;
- RCT/IPW EOM evaluator;
- PPL loss。
目标:确认数据口径、预算约束、EOM 指标与 solver 正确。
Stage 2:OBS + Teacher + fixed Bridge sanity check
先在 RCT 上训练 Teacher,OBS 上训练 Target。Bridge 可以先做固定 gate:
测试 。如果固定 gate 都不稳定,直接上 bi-level 没意义。
Stage 3:learned Bridge + explicit bi-level
每 个 batch copy Target,做 步 assumed lower update,用 RCT PPL 上层 loss 更新 Bridge。先不做 CG/ID,验证 Bridge 是否真的学到非平凡 gate。
需要监控:
防止 gate collapse 到全 0 或全 1。
Stage 4:implicit differentiation + CG
实现 HVP、CG、damping、residual logging。需要监控的量:
避免非正定 Hessian 或数值爆炸。
Stage 5:PIFD 增强
PPL 稳定后再做 PIFD。PIFD 的首要任务并不是“按公式实现”,而是验证有限差分给出的梯度方向,是否与 brute-force small batch perturbation 一致。
20. 数据与实验前提
最小字段:
| 字段 | 说明 |
|---|---|
| 用户/商家/商品/上下文特征 | |
| 实际 treatment | |
| revenue/order/gmv/profit outcome | |
| coupon/subsidy cost | |
| data source flag | RCT or OBS |
| RCT/OBS logging probability,至少 RCT 需要已知 | |
| attribution window | outcome/cost 的归因窗口 |
| budget | 训练/评估预算或候选预算集合 |
关键假设/风险:
- Consistency:观测到的 确实等于潜在结果 ;
- Positivity/overlap:每个重要人群/treatment 在 RCT 中有足够覆盖;
- No interference:个体之间无干扰。营销场景经常不完全成立;
- RCT 与 OBS 可比:时间、人群、活动机制不能漂移太大;
- 成本口径稳定: 的归因要和预算消耗一致;
- 收益口径稳定: 不能只看订单而忽略毛利/退款/长期价值,除非业务目标就是订单。
21. 论文评价:优势、局限与可信度判断
优势
- 问题定义非常贴近工业营销:多 treatment、预算约束、revenue/cost 双输出、OBS/RCT 混合。
- 不是简单数据融合:RCT 在上层控制 OBS 的使用方式,而不是 concat。
- 实验完整度高:公开 hybrid、两个工业数据、主结果、消融、数据量、预算鲁棒性、训练时间、线上 A/B 都有。
- 上线复杂度可控:训练复杂,但 inference 只用 Target + solver。
- PPL 这个简化版本很实用:比 PIFD 更容易复现,也在线上表现接近。
局限/不清楚处
- Bridge 输入与结构细节不够展开:正文写 ,但工业实现需要明确输入表示。
- pseudo-label 中 Target 分支 detach 不明确:这是复现成败关键。
- RCT estimator 的方差控制不足: 或 在稀疏 treatment 下可能高方差。
- online A/B 指标披露有限:缺预算消耗、ROI、profit、绝对量、分层结果。
- 无 interference 假设在商家/折扣场景可能不完全成立:折扣可能影响用户在商家间迁移。
- 工业数据不可公开:核心结论依赖两个美团数据和线上系统,外部复现难。
落地判断
这篇论文对优惠券/补贴个性化的参考价值较高。它的理论贡献不在于发明全新因果估计器,而在于把 RCT 作为决策质量校正器、把 OBS 作为大规模训练载体、把 预算优化器作为训练目标的一部分 结合起来。
如果目标是短期落地,优先复现 Bi-DFCL-PPL 的简化版;如果目标是形成长期方法壁垒,再研究 Bridge + implicit differentiation + PIFD。
22. 核心公式链条
整篇论文可以用这条链条串起来:
1. 下游优化器
2. RCT 上的无偏决策估计
3. PPL 可微 surrogate
4. Bridge counterfactual pseudo-label
5. OBS 下层 prediction loss
6. Bi-level objective
7. Implicit gradient
这条链条就是 Bi-DFCL 的核心:用 RCT 上可微/近似可微的 decision signal,通过 implicit bi-level gradient,控制 OBS 上的 counterfactual prediction learning。